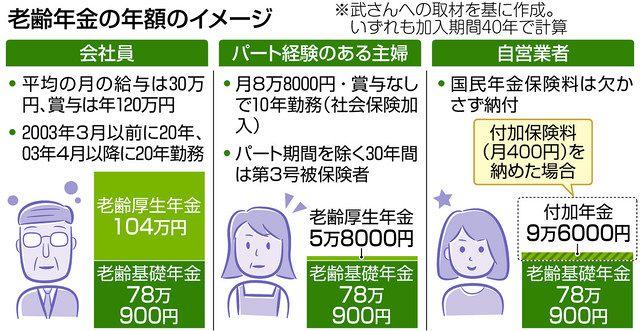
このブログは2021年8月24日に David DeLuca (Senior Storage Solution Architect)によって執筆された内容を日本語化した物です。原文はこちらを参照して下さい。
オンプレミスからクラウドへデータを移行する際には、スピード、効率、ネットワーク帯域、コストなど、考慮すべき要素が数多くあります。多くの企業が直面する共通の課題は、大量のデータをオンプレミスから Amazon S3 バケットにコピーする際の適切なユーティリティの選択です。
私はよく、お客様が無料のデータ転送ユーティリティーや AWS Snow Family デバイスを使って、データをS3に取り込むことから始めるケースを目にします。また、同じお客様が AWS DataSync を使用して継続的な増分変更をキャプチャすることもあります。
1つのツールを使用してデータを S3 に最初にコピーし、DataSync を使用して増分更新を適用するというこの種のシナリオでは、考慮すべきいくつかの疑問があります。別のデータ転送ユーティリティで書き込まれたファイルを含む S3 バケットにデータをコピーする場合、DataSync はどのように動作するのか? DataSync は既存のファイルがオンプレミスのファイルと一致することを認識するのか?データの2つ目のコピーが S3 に作成されるのか、データを再送信する必要があるのか?等の疑問です。
追加の時間、コスト、および帯域幅の消費を避けるためには、DataSync が「変更された」データをどのように識別するかを正確に理解することが重要です。DataSync はオブジェクトメタデータを使用して増分的な変更を識別します。データが DataSync 以外のユーティリティーを使用して転送された場合、このメタデータは存在しません。この場合、DataSync は増分変更をS3に適切に転送するために追加の操作を行う必要があります。最初の転送にどのストレージクラスを使用したかによっては、予想外のコストが発生する可能性があります。
この記事では、オンプレミスのデータを S3 バケットにコピーすることについて、以下の3つの異なるシナリオを検討し、それぞれ独自の結果を得ることができるようにしました:
- DataSync を使用して最初のコピーとすべての増分変更を実行。
- DataSync を使用して、DataSync 以外のユーティリティで書き込まれた次のようなストレージクラスのデータを同期する。S3 Standard、S3 Intelligent-Tiering (Frequent Access または Infrequent Access tier)、S3 Standard-IA、または S3 One Zone-IA。
- DataSync を使用して、DataSync 以外のユーティリティで書き込まれた次のようなストレージクラスのデータを同期する。S3 Glacier、S3 Glacier Deep Archive、または S3 Intelligent-Tiering (Archive Access または Deep Archive Access 層)
各シナリオの詳細な結果を確認した後は、予期せぬ料金が発生することなく、効率的に Amazon S3 にデータを移行・同期するための DataSync の使用方法を決定出来ます。
ソリューション概要
DataSync は、オンプレミスのストレージシステムと AWS ストレージサービスの間でのデータ移動に加え、AWS ストレージサービス間でのデータ移動を簡素化、自動化、高速化するオンラインデータ転送サービスです。DataSync は、アクティブなデータセットの AWS への移行、オンプレミスのストレージ容量を空けるためのデータのアーカイブ、事業継続のための AWS へのデータのレプリケーション、分析や処理のためのクラウドへのデータ転送などに利用できます。
ここでは、DataSync がオンプレミスから AWS のストレージサービスへのデータ転送にどのように使用できるかを確認してみましょう。DataSync エージェントは、オンプレミスのストレージシステムからデータを読み書きするために使用される仮想マシン (VM) です。エージェントは AWS クラウドの DataSync サービスと通信し、AWS ストレージサービスへのデータの実際の読み書きを行います。
DataSync タスクは、データが転送されるロケーションのペアで構成されます。タスクを作成する際には、転送元と転送先の両方のロケーションを定義します。DataSync の設定に関する詳細な情報は、ユーザーガイドをご覧ください。
次の図は、私のテスト環境のアーキテクチャを示しています。ソースロケーションは、オンプレミスの Linux サーバーでホストされているネットワークファイルシステム (NFS) 共有のセットです。ターゲットロケーションは、バージョニングが有効な S3 バケットです。3つの DataSync タスクが設定されており、各シナリオごとに1つずつ、以下のタスクオプションを使用しています。
DataSync の内部構造を深く理解するために、私は3つのツールを利用しています:
Amazon S3の簡単な説明
このブログでは、S3 バケットへのデータ転送に焦点を当てていますので、関連するトピックを確認してみましょう。Amazon S3 は、業界トップクラスのスケーラビリティ、データ可用性、セキュリティ、パフォーマンスを提供するオブジェクトストレージサービスです。
S3 ストレージクラス
S3 では、様々なアクセスパターンに対応したストレージクラスが用意されています。
DataSync では、任意の S3 ストレージクラスに直接書き込むことができます。
S3 メタデータ
Amazon S3 にファイルデータをコピーする際、DataSync は自動的に各ファイルを1対1の関係で単一の S3 オブジェクトとしてコピーし、ソースファイルの POSIX メタデータを Amazon S3 オブジェクトのメタデータとして保存します。DataSync タスクが “transfer only data that has changed” に設定されている場合、DataSync はファイルのメタデータと対応するオブジェクトの S3 メタデータを比較して、ファイルを転送する必要があるかどうかを判断します。次の図は、DataSync が書き込んだ S3 オブジェクトのメタデータの例です。
S3 API オペレーション
S3 は REST API 規格をサポートしています。これにより、S3 のバケットやオブジェクトにプログラムでアクセスすることができます。このブログでは、以下のアクションを中心にご紹介します:
S3 バージョニング
Amazon S3 バージョニングは、あるオブジェクトの複数の世代を同じバケットに保持する手段です。S3 バージョニング機能を使用して、バケットに保存されているすべてのオブジェクトのすべてのバージョンを保存、取得、復元することができます。DataSync を使用して S3 バケットにデータを転送する際には、バージョニングの影響を慎重に考慮する必要があります。
ウォークスルーシナリオ
シナリオ1: DataSync を使ってS3バケットへのデータの初期同期を行う。
このシナリオでは、オンプレミスの NFS 共有から空の S3 バケットにファイルを転送するデモを行います。このシナリオは、シナリオ2および3に関連した DataSync の動作を理解するためのベースラインを設定します。DataSync は最初の同期に使用されているため、S3 ストレージクラスは動作に影響しません。
- オンプレミスの NFS 共有には、2つのファイルが含まれています。”TestFile1″と “TestFile2″です。S3 バケットは空です。DataSync タスクを実行して、NFS ファイルをS3に転送します。このタスクが完了すると、以下のようになります。:
- NFS 共有に2つのファイルを追加します(”TestFile3″と”TestFile4″)。2回目の DataSync タスクを実行します。タスクが完了すると、次のようになります。:
- NFS 共有に新しいファイルを追加せず、3回目の DataSync タスクを実行します。タスクが完了すると、次のようになります。:
シナリオ2: DataSync を使用して、ストレージクラスが Standard、S3 Intelligent-Tiering (Frequent または Infrequent Access tier)、S3 Standard-IA、または S3 One Zone-IA である既存の S3 データとデータを同期する。
最初のシナリオとは異なり、S3 バケットは空ではありません。S3 バケットには、オンプレミスのファイル共有にある2つのファイルと同じデータである2つのオブジェクトが含まれています。しかし、このファイルは DataSync 以外のユーティリティを使用して S3 にアップロードされたため、POSIX メタデータがありません。
- オンプレミスの NFS 共有には、2つのファイルが含まれています。”TestFile1″と “TestFile2″です。S3バケットには、同じデータのコピーが、ストレージクラス”Standard”で格納されています。
- NFS 共有に2つのファイルを追加します(”TestFile3″と”TestFile4″)。最初の DataSync タスクを実行します。完了すると、次のようになります。:
- NFS 共有に新しいファイルを追加せず、2回目の DataSync タスクを実行します。タスクが完了すると、次のようになります。:
シナリオ3: DataSync を使用して、ストレージクラスが Amazon S3 Glacier、S3 Glacier Deep Archive、またはS3 Intelligent-Tiering (Archive または Deep Archive層) である既存の S3 データとデータを同期する。

これはシナリオ2と似ていますが、S3 バケットは空ではありません。S3 バケットには、オンプレミスのファイル共有にある2つのファイルと同じデータである2つのオブジェクトが含まれています。このファイルは DataSync 以外のユーティリティを使用して S3 にアップロードされたため、POSIX メタデータを持っていません。しかし、前のシナリオとは異なり、このオブジェクトは長期的なアーカイブを目的としたストレージクラスに存在します。
- オンプレミスの NFS 共有には、2つのファイルが含まれています。”TestFile1″と “TestFile2″です。S3 バケットには、Amazon S3 Glacier ストレージクラスに同じデータのコピーが含まれています。
- NFS 共有に2つのファイルを追加します(”TestFile3″と”TestFile4″)。最初の DataSync タスクを実行します。タスクが完了すると、次のようになります。:
- NFS 共有に新しいファイルを追加せず、2回目の DataSync タスクを実行します。タスクが完了すると、次のようになります。:
まとめ
このブログでは、AWS DataSync が空の S3 バケットにデータをコピーする際に、既存のデータがある S3 バケットと比較して、どのように動作するかを深堀りしてみました。以下が得られた知見です。:
シナリオ1では、DataSync はオンプレミスから空の S3 バケットへの最初のコピーを実行しました。DataSync は、ファイルと必要なメタデータをワンステップで書き込むことができました。これは非常に効率的なプロセスであり、ネットワークの帯域幅を有効に活用し、時間を節約でき、全体的なコストを削減できる可能性があります。最も重要なのは、どの Amazon S3 ストレージクラスでも動作するという利点があることです。
シナリオ2は、S3 ストレージクラスが Standard、S3 Intelligent-Tiering (Frequent or Infrequent Access tier)、S3 Standard-IA、S3 One Zone-IA のいずれかである場合で、過去に転送した S3 データとのデータ同期を行いました。データを有線で再送信する必要はありませんでしたが、各 S3 オブジェクトの新しいコピーが作成されました。この方法でも、帯域幅の効率化は図れますが、GET と COPY の操作に追加の S3 リクエスト料金が発生します。
シナリオ3は、S3 ストレージクラスが Amazon S3 Glacier、S3 Glacier Deep Archive、S3 Intelligent-Tiering(Archive または Deep Archive 層)のいずれかである場合で、過去に転送した S3 データとの同期を行いました。この方法では、各ファイルを有線で再送信する必要がありました。これは、S3 リクエストの追加料金、帯域幅の使用量の増加、および時間の増加につながるため、最も効率の悪い方法です。
S3 のストレージクラスに関わらず、バケットで S3 のバージョニングが有効になっている場合、過去に転送された S3 データと同期すると、各オブジェクトの重複コピーが作成されます。この結果、シナリオ2と3の両方で示されているように、S3 ストレージの追加コストが発生します。
データの継続的な同期に DataSync を使用しているのであれば、S3 への最初の転送は可能な限り DataSync で行うことをお勧めします。ただし、DataSync 以外の手段で S3 にデータをコピーした場合は、ストレージクラスが Amazon S3 Glacier、S3 Glacier Deep Archive、S3 Intelligent-Tiering (Archive または Deep Archive tier) でないことを確認してください。また、そのバケットの S3 Versioning が現在有効になっている場合は、それを停止することをお勧めします。
AWS DataSync と Amazon S3 についてお読みいただきありがとうございます。